I recently learned about the Custom Extraction tool in Screaming Frog, which you can use to scrape any specific data from a web page. So I tested it out to grab the published and modified date and time for my competitor sites to get an overview of how often they produce/edit content on their website.
And unlike everything that I tried for the first time, it worked, and it worked well. So, I decided to share with everyone who, like me, would love to take advantage of this handy feature from Screaming Frog.
Table of Contents
- So what do you need for it?
- What should you know before getting to it?
- Steps to Extract the Published and Modified Date/Time
- Conclusion
So what do you need for it?
Just a simple tool most of you would have already had – A paid license to Screaming Frog SEO Spider.
What should you know before getting to it?
You can skip directly to the next section if you just want to get to the task. But for those curious ones like me, I want to share how this works so that you are not limited to the example code I share below and can use this method to its maximum capabilities.
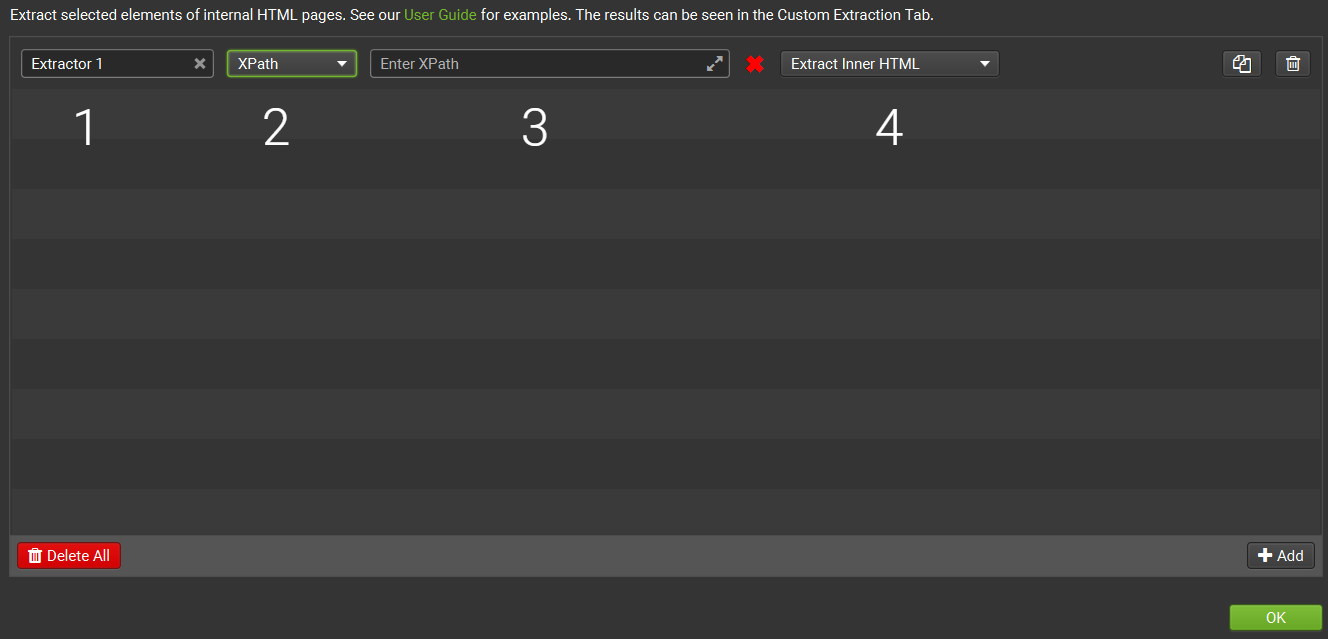
1. Name
This will be the name of the column heading you will see in the Screaming Frog Custom Extraction report. You can let it be Extractor 1 or change it to something like Published Date, Modified Date, etc.
2. Method of Extraction
So there are three methods you can use to scrape specific data from a webpage’s HTML, i.e., using
- XPath,
- CSS Path,
- or Regex.
XPath is the most common one. CSS Path is the quickest one. A regex is an advanced way to grab text with matching patterns (like comments or inline JS).
3. XPath or CSS Path or Regex
As you can guess, here, we‘ll have to enter the Paths or Regex function.
4. Options for What to Extract
Now there are four ways to select what we want to extract –
- Extract Inner HTML: This is the default option that extracts inner HTML content (even other elements if they are in inner HTML).
- Extract HTML Element: This will extract the element you selected and whatever inner HTML content it has.
- Extract Text: It extracts the text content of the element you selected.
- Function Value: You can use it to apply various kinds of functions (like the count function to count the number of paragraphs, headings, etc., in a webpage).
Note: If the element you want to grab is only available in rendered HTML, you need to enable the JS Rendering mode first from the Spider Configuration.
Now that you have understood all the options, it would be a waste if you don’t take advantage of all the use cases of the Custom Extraction feature. Screaming Frog’s blog itself provides various ways you can use it to extract elements like email addresses, hreflang, links to a specific domain, or just in the body section, etc.
Steps to Extract the Published and Modified Date/Time
Now for the steps, let’s just get to it:
- Open Screaming Frog, and from the top menu, go to Configuration > Custom > Extraction.
- In the Custom Extraction window, click the “Add” button at the bottom right corner.
- In the “XPath” field, enter the XPath expression that targets the published date on the site:
//meta[@property='article:published_time']/@content
- You will see a green tick next to the expression you entered, which means it is valid.
- Click on the “Save” button to save the custom extraction configuration.
- Repeat steps 2-5 to add the modified date. The only change here you need to make is to enter this XPath expression instead of the one you entered for extracting the published date:
//meta[@property='article:modified_time']/@content
Note: If you are looking for published/modified dates of pages that are not from a WordPress site, there can be other ways to look for them. First, you need to view the page source (Ctrl + U) for any web page and find if the element for showing published or modified dates exist or not. If not, then you can’t do anything about it, but if they are present, then the easiest way is just to ask ChatGPT to create an XPath for you from the code.
Note: Also, in most cases, the published and modified date/time is present in the schema of a site’s web pages. Then you can use the following expressions (make sure to use Regex mode instead of XPath for this):
["']datePublished["']: *["'](.*?)["']
["']dateModified["']: *["'](.*?)["']

- Now enter the URL of the WordPress site you want to crawl in the “Enter URL to spider” field at the top and click on the “Start” button.
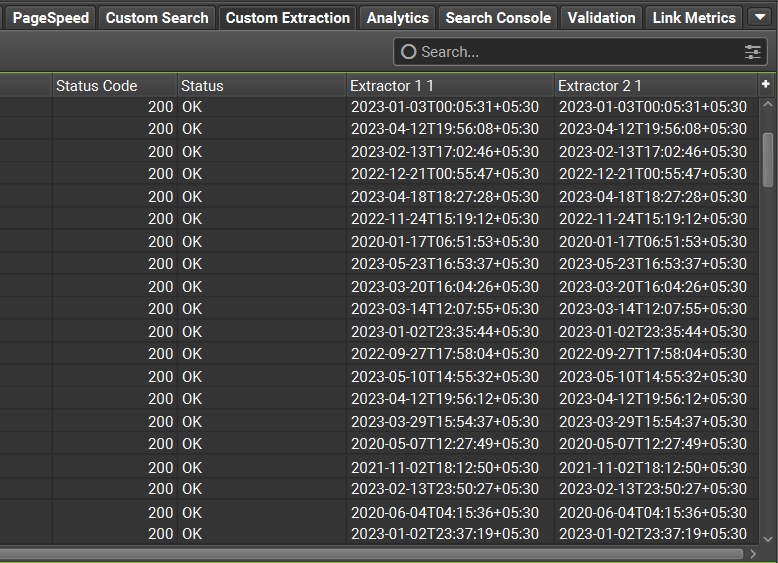
- Once the crawling is complete, go to the “Custom Extraction” tab.
- There you can find the published and modified date for the webpages in Extractor 1 and Extractor 2 columns shown below.
Conclusion
I hope you will find it helpful for your competitor analyses in the future, and I will try to add more such guides in the future, so stay tuned. Or you can also follow me on my Twitter or Mastodon, where I post more stuff regularly.
Lastly, please feel to reach out in the comments below or use my contact page if you need more help.
Thankyou for this article. I have been following it.
🙂
Great tutorial! The step-by-step instructions were easy to follow and helped me extract the published dates of all pages on my site effortlessly. I appreciate the detailed explanations and screenshots provided, making it a smooth process. Thank you for sharing this valuable information! – GPTOnline
Thanks for your comment 🙂